|
|
|
|
|
민감 데이터를 서버로 직접 보내지 않고도 고품질 이미지 생성을 돕는 초경량 인공지능 모델이 개발됐다. 환자 MRI, CT 분석 등 개인 정보 보호가 중요한 환경에서 고성능 생성 AI를 안전하게 활용할 수 있는 길이 열렸다. UNIST 인공지능대학원 유재준 교수팀은 연합학습 AI 모델인 프리즘(PRISM, PRivacy-preserving Improved Stochastic Masking)을 개발했다고 밝혔다. 연합 학습은 민감 정보가 포함된 데이터를 직접 서버에 올리지 않고, 각자 장치의 ‘로컬AI’가 학습을 수행한 뒤 그 결과만을 모아 하나의 ‘글로벌 AI’를 만드는 기술이다. 프리즘은 연합학습 과정에서 로컬 AI와 글로벌 AI를 연결하는 학습 중재자 역할의 AI 모델이다. 이 모델은 기존 모델보다 통신 비용을 평균 38% 줄이고, 그 크기는 48% 감소한 1-bit 수준의 초경량형이라 스마트폰, 태블릿 PC 같은 소형 장비의 CPU나 메모리에 부담 없이 작동한다. 또 로컬 AI마다 가진 데이터와 성능의 편차가 큰 상황에서도 어떤 로컬 AI의 정보를 더 믿고 반영할지를 정확하게 판단해 조율하기 때문에 최종 생성물의 품질이 높다. 가령 ‘셀카’를 지브리풍으로 바꿀 때 기존에는 사진을 서버에 올려야 해 개인정보 침해 우려가 있었다면, 프리즘을 이용하면 모든 처리가 스마트폰 안에서 이뤄져 사생활 침해를 막고 결과도 빠르게 받아볼 수 있는 것이다. 단, 스마트폰에서 이미지를 직접 생성하는 로컬 AI 모델 개발은 별도로 필요하다. 실제 AI 성능 검증에 쓰이는 데이터셋인 MNIST, FMNIST, CelebA, CIFAR10로 실험한 결과, 기존 방식보다 통신량은 적으면서도 이미지 생성 품질은 더 높게 나타났다. 특히 MNIST 데이터셋을 이용한 추가 실험에서는, 지브리풍 이미지를 생성하는 데 주로 쓰는 디퓨전 모델과의 호환성도 확인했다. 연구팀은 모든 정보를 공유하는 대용량 파라미터 방식 대신, 중요 정보만 선별해 공유하는 이진 마스크 방식을 적용해 통신 효율을 높였다. 또 생성 품질을 정밀하게 평가하는 손실 함수(MMD, Maximum Mean Discrepancy)와 각 로컬 AI의 기여도를 다르게 집계하는 전략(MADA, Mask-Aware Dynamic Aggregation)으로 데이터 편차와 학습 불안정성을 해소했다. 유재준 교수는 "이미지뿐만 아니라, 텍스트 생성, 데이터 시뮬레이션, 자동 문서화 등 다양한 생성 AI 분야에 적용할 수 있다"며 "의료, 금융 등 민감 정보를 다루는 분야에서 효과적이고 안전한 솔루션이 될 것"이라고 말했다. 이번 연구는 연세대학교 한동준 교수와 함께했으며, UNIST 서경국 연구원이 제1 저자로 참여했다. 연구결과는 세계 3대 인공지능 학회 중 하나인 ICLR(The International Conference on Learning Representations) 2025에 채택됐다. 2025 ICLR은 4월 24일부터 28일까지 5일간 싱가포르에서 열린다. 연구 수행은 과학기술정보통신부 한국연구재단, 정보통신기획평가원, UNIST 슈퍼컴퓨팅센터의 지원을 받아 이뤄졌다. (논문명: PRISM: PRivacy-preserving Improved Stochastic Masking for Federated Generative Models) |
|
|
|
[붙임] 연구결과 개요 |
|
1.연구배경 고성능 생성 모델의 발전은 이미지 합성, 변환, 영상 생성 등 다양한 응용 분야에서 뛰어난 성과를 이끌어냈다. 그러나 이러한 모델의 학습에는 대규모의 데이터와 고성능 연산 자원이 필수적이며, 최근에는 공공 학습 데이터의 고갈로 인해 학습 데이터 확보에 어려움이 커지고 있다. 이에 따라, 스마트폰·스마트워치·센서·병원 시스템 등 다양한 플랫폼에 분산되어 있는 사용자 데이터를 안전하게 활용할 수 있는 방법에 대한 관심이 높아지고 있으며, 프라이버시를 보장하면서 협력 학습이 가능한 ‘연합 학습(Federated Learning, FL)’이 유력한 대안으로 주목받고 있다. 연합학습은 각 로컬AI가 로컬 데이터를 직접 중앙 서버에 모으거나 공유하지 않고, 로컬AI의 업데이트만을 서버에 전달함으로써 하나의 글로벌 모델을 공동으로 학습하는 프레임워크이다. 이는 데이터 활용성과 개인정보 보호 간의 균형을 동시에 달성할 수 있다는 점에서 다양한 분야에서 각광받고 있다. 하지만 연합학습 환경에서 생성 모델(generative model)을 학습하는 일은 여전히 많은 도전 과제를 안고 있다. 특히 이미지나 영상처럼 고차원 데이터를 생성해야 하는 경우, 로컬AI 간 이질적인 데이터 분포(non-IID), 통신 비용의 급증, 민감한 정보 보호 요구, 분류 모델에 비해 훨씬 어려운 생성 태스크의 학습 안정성 부족 등의 문제가 있다. 기존 연구는 대부분 GAN 기반 접근에 한정되어 있으며, 복잡한 데이터셋(CelebA, CIFAR10 등)에서는 안정적인 학습조차 어려운 상황이다. 현재까지의 연합학습 연구는 주로 분류(classification) 모델에 집중되어 있으며, 생성 모델을 대상으로 한 연구는 극히 제한적이고 실용화 수준에 미치지 못하고 있다. 특히, 고복잡도 데이터셋에서의 고품질 생성과 실용적인 학습 구조를 동시에 만족시키는 프레임워크는 부재한 실정이다. 이에 본 연구는 이러한 한계를 극복하기 위해, 제한된 자원 환경에서도 강력한 성능과 프라이버시 보호를 동시에 달성할 수 있는 새로운 생성 모델 학습 프레임워크를 제안한다. 특히, 정보 보안, 통신 효율, 학습 안정성을 동시에 고려한 설계를 통해, 현실적인 연합학습 환경에서도 고품질 생성이 가능한 경량화된 학습 구조를 구축하는 것을 목표로 한다. 2.연구내용 본 연구에서는 이러한 문제를 해결하기 위해 PRISM(PRivacy-preserving Improved Stochastic-Masking)이라는 새로운 연합학습 생성 모델 학습 프레임워크를 제안했다. PRISM은 Strong Lottery Ticket(SLT) 기반 이진 마스킹 학습 전략을 택한다. 모델의 가중치를 직접 업데이트하는 대신, 초기화된 무작위 네트워크에서 성능이 뛰어난 희소 서브네트워크(Strong Lottery Ticket)를 이진 마스크로 탐색하는 것이다. 각 로컬AI는 이진 마스크만을 서버로 전송하므로, 전체 파라미터를 주고받는 기존 방식 대비 통신 비용을 획기적으로 절감할 수 있다. 이를 통해 통신 비용을 평균 38%, 최대 63.1% 줄였다. 또 MMD 기반 로컬 학습 안정화를 적용했다. 로컬 AI는 VGG 기반 특성 공간에서 생성 이미지와 실제 데이터의 차이를 MMD(Maximum Mean Discrepancy) 손실로 정량화하여, 생성 모델의 학습 안정성을 확보한다. MADA(Mask-Aware Dynamic Aggregation)를 적용해 각 로컬AI의 이진 마스크와 서버 마스크 간의 유사도를 기반으로, 로컬 AI의 드리프트(client drift)를 완화하는 동적 평균 전략을 설계했다. 이를 통해 별도 하이퍼파라미터 없이 안정적인 수렴을 가능하게 한다. 이 모델은 가중치 초기화를 통해 별도 양자화 없이도 1-bit 형태로 표현가능하며, 추론 시에도 경량화된 구조로 동작할 수 있다. 이는 기존보다 48% 줄어든 크기이다. 또 마스크와 점수 정보를 혼합하여 성능과 통신 비용 간의 균형을 조절할 수 있도록 설계되어, 응용 환경에 맞는 조정이 가능하다. 3.기대효과 PRISM은 보안상 데이터를 직접 전송할 수 없는 다양한 분야에서 연합학습을 효과적으로 적용할 수 있다. PRISM은 GAN 기반 기존 연합학습 생성 모델이 갖는 불안정성과 확장성 한계를 구조적으로 극복한 모델로 ‘프라이버시 보장 + 복잡한 데이터 생성 간소화 + 통신 효율성’ 세 가지를 동시에 만족한 생성 모델 학습 프레임워크이다. 모바일·엣지 디바이스 환경에서의 프라이버시 중심 생성 모델 학습을 실현함으로써, 향후 의료 영상 생성, 사용자 맞춤형 콘텐츠 생성, 사적 데이터 기반 추천 시스템 등 다양한 분야에 응용 가능하다. 특히 프라이버시 보호가 중요한 금융, 헬스케어, 스마트 홈, 퍼스널 AI 등에서 중앙 서버에 데이터를 올리지 않고도 고품질 생성이 가능해짐으로써, 실제 서비스로의 이행 가능성이 높다. 통신 비용은 기존 대비 최대 60% 이상 절감되며, 최종 모델 사이즈는 절반 이하로 경량화되어 저전력 디바이스에도 쉽게 배포 가능하다. 이를 통해 클라우드 자원 소비를 줄이며 탄소 발자국 저감과 지속 가능성 측면에서도 기여할 수 있다. |
|
[붙임] 용어설명 |
|
1.연합학습 분산된 엣지 디바이스 환경에서 각각의 AI 모델을 업데이트 후, 서버에서 모델 업데이트를 병합(aggregation)하여 강력한 글로벌 모델을 학습하는 인공지능의 학습전략 2.Non-IID (이기종 데이터) 각 클라이언트(로컬AI)가 소유하고 있는 데이터 분포가 상이한 상황. 3.최대평균불일치(Maximum Mean Discrepancy) 두 분포를 각각 Reproducing Hilbert Kernel Space (RKHS) 로 매핑한 뒤, 매핑된 분포의 평균 사이의 거리를 측정하는 거리함수. AI가 만든 이미지와 실제 이미지가 얼마나 다른지 수학적으로 비교하는 기준으로, 각 로컬 AI가 전체 모델과 너무 다른 결과를 만들지 않도록 조정해주는 역할을 한다. 4.확률적 이진 마스크(Stochastic binary mask) 학습된 score 파라미터를 sigmoid, bernoulli 함수를 통해 확률적으로 매핑된 이진 마스크. 로컬 AI가 학습한 결과 중에서 어떤 부분을 서버에 보낼지를 확률적으로 선택해 만든 ‘0 또는 1’로 된 마스크 형태의 정보로, 전체 데이터를 보내지 않고도 중요한 정보만 공유해 통신량을 줄이는 데 기여한다. 5. 입실론 델타-differential privacy(DP) 송수신되는 모델 업데이트로부터 로컬 데이터 추출을 막기 위해 추가적으로 랜덤성을 가하는 기법. 입실론, 델타 파라미터에 의해 강도를 조절할 수 있다. AI가 학습한 정보를 바탕으로 원래 데이터를 유추하지 못하도록 ‘가짜 정보’를 일부 섞는 기술로 서버에 보낸 정보만으로는 개인 정보를 유추할 수 없게 만들어 보안성을 높인다. |
|
[붙임] 그림설명 |
|
그림1. PRISM의 작동 방식. PRISM은 연합학습 환경에서 통신 부담을 줄이기 위해 ‘글로벌 이진 마스크’를 찾아내는 방식으로 동작한다. 먼저 각 기기(클라이언트)는 자신이 중요하다고 판단한 모델 부분을 점수로 계산해 로컬 이진 마스크를 만든다. 이후 필요에 따라 (ε, δ)-디퍼렌셜 프라이버시 기법을 적용해 개인 정보 보호를 강화한 채 글로벌 이진 마스크를 생성한다. 이렇게 만들어진 글로벌 마스크는 이전 단계 결과와의 연관성을 고려해 더 정교하게 조정되고, 다시 각 클라이언트로 전송되어 다음 학습 단계로 이어진다.
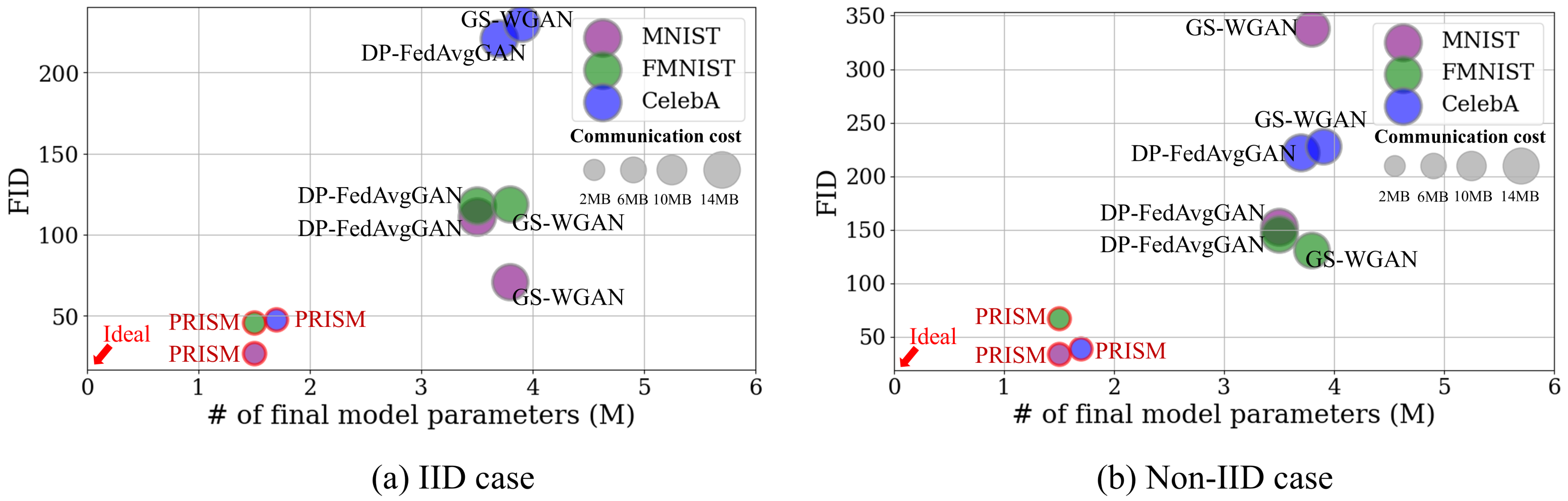
그림2. 다양한 데이터 환경에서의 성능 비교. x축은 각 모델의 최종 모델 파라미터, y축은 생성 품질(FID)을 의미한다. 통신 비용은 원의 크기로 나타내었고, 좌측하단에 가깝고 원의 크기가 작을수록 이상적인 성능을 나타낸다.
그림3. 데이터셋을 이용한 생성형 이미지 비교. 각 행은 순서대로 MNIST, FMNIST, CelebA 데이터셋을 이용한 생성 이미지를 나타낸다. 기존 방식보다 PRISM이 더 자연스럽고 품질 높은 이미지를 생성함을 확인할 수 있다. |
|
|
UNIST 홍보팀 news@unist.ac.kr TEL : 052)217-1230FAX : 052)217-1229 |




![[연구그림] 개발된 연합학습 AI의 작동 방식](https://news.unist.ac.kr/kor/wp-content/uploads/2025/04/연구그림-개발된-연합학습-AI의-작동-방식.png)
![[연구그림] 데이터셋을 이용한 생성형 이미지 비교](https://news.unist.ac.kr/kor/wp-content/uploads/2025/04/연구그림-데이터셋을-이용한-생성형-이미지-비교.png)