|
|
|
|
|
인공지능에게 한 유형의 데이터만 가르쳐서, 다른 유형의 데이터 학습을 촉진 시킬 수 있는 학습 방식이 개발됐다. 서로 다른 유형의 데이터 학습에서 꼭 필요하다고 여겨지던 데이터 정렬 작업 없이도 학습이 가능해져 데이터셋 구축 비용 등을 절감할 수 있을 것으로 기대된다. UNIST 인공지능대학원 윤성환 교수팀은 데이터 정렬과 매칭 없이 하나의 데이터 유형만으로 다른 유형의 모델 학습을 촉진 시킬 수 있는 AI 멀티모달 학습 기술을 개발했다고 7일 밝혔다. 멀티모달 학습은 오디오, 이미지, 텍스트와 같이 서로 다른 데이터 모달리티를 결합해 통합적으로 이해하고 처리하는 학습법이다. 멀티 모달 학습을 위해서는 다양한 모달리티 데이터를 정렬하고 이에 대해 쌍을 이루는 라벨링 과정이 필요해 많은 시간과 비용이 소모된다. 또 명확히 짝지어진 데이터가 부족하면 성능이 저하되기까지 했다. 연구팀이 제안한 학습법은 짝지어지지 않은 데이터로도 멀티 모달 학습이 가능하다. 음성과 인간 표정을 함께 분석해 감정을 이해하는 AI 비서나, CT 영상과 진료 기록을 의사처럼 결합해 진단하는 의료AI 구축에 들어가는 비용과 시간을 절감할 수 있다. 연구팀은 텍스트 모델이 이미지 모델 학습을 돕거나, 오디오 모델이 언어 모델 성능을 높이는 등의 실험을 진행했고, 기존보다 높은 정확도를 기록하며 모달리티 간 학습 촉진 효과를 확인했다. 특히, 오디오와 이미지처럼 직접적인 연관성이 적은 조합에서도 AI의 성능 향상이 나타났다. 제1저자인 이재준 연구원은 “서로 관련 없어 보이는 오디오와 이미지 조합에서도 성능이 향상된 것은, 기존 멀티모달 학습 방식에 대한 고정관념을 깨는 흥미로운 결과”라고 설명했다. 윤성환 교수는 “정렬된 데이터셋 확보가 어려운 의료, 자율주행, 스마트 AI 비서 등 다양한 분야에서 활용 가능성이 높다”고 말했다. 이번 연구결과는 세계 인공지능 3대 학회인 ICLR(International Conference on Learning Representations) 2025에 채택됐다. ICLR 2025는 지난 4월 24일부터 28일까지 싱가포르에서 개최됐으며, 11,672편의 논문 중에서 3,646편이 채택됐다. (논문명: Can One Modality Model Synergize Training of Other Modality Models?)
|
|
|
|
[붙임] 연구결과 개요 |
|
1.연구배경 최근 AI 기술의 발전으로 인해 대형 멀티모달 모델(Large Multimodal Model, 이하 LMM)이 주목받고 있다. 멀티모달 학습은 서로 다른 유형의 데이터를 결합하여 보다 정교한 모델을 구축하는 방법으로, 이미지와 텍스트, 오디오와 텍스트 등 다양한 형태의 데이터를 활용할 수 있다. 그러나 기존의 멀티모달 학습 방식은 몇 가지 한계점을 지니고 있다. 첫째, 고품질의 정렬된 데이터셋이 필요하다. 기존 멀티모달 모델을 학습시키기 위해서는 각 모달리티 간의 데이터가 정확하게 매칭시키면서 학습을 진행하였기 때문에 잘 매칭된 형태의 데이터가 필요로 하다. 둘째, 멀티모달 모델이 좋은 성능을 내려면 대규모의 데이터셋이 필요로 하는데, 이러한 데이터셋을 구축하는 데에는 막대한 비용이 소요되며, 적용할 수 있는 분야가 제한적이다. 또한, 기존 연구들은 여러 모달리티를 동시에 학습할 경우 모델의 성능이 향상된다는 사실을 실험적으로 입증하였으나, 한 모달리티가 다른 모달리티의 학습을 촉진하는 메커니즘에 관한 이론적 연구는 많이 없었다. AI 연구에 있어 이론적 근거는 필수적이지 않지만, 이론적 근거 없이 연구를 진행할 때 연구의 확장성과 일반화가 저해될 수 있다. 따라서 멀티모달 학습의 접근성을 높이기 위해서는 이론적 근거를 마련하고, 이를 기반으로 다양한 연구를 수행해야 할 필요가 있다. 2.연구내용 이번 연구의 핵심은 한 모달리티 모델이 다른 모달리티 모델의 학습을 도울 수 있는지에 대한, 한 모달리티 모델을 학습하는데 있어서 다른 모달리티 모델을 통해 시너지를 낼 수 있는지(synergestic multimodal learning)에 대한 이론적·실험적 검증이다. 연구팀은 "텍스트 모델이 이미지 모델의 학습을 돕거나, 오디오 모델이 언어 모델의 성능을 높일 수 있는가?"라는 질문을 던지고 이를 수학적으로 분석했다. 연구팀은 와서스테인 거리(Wasserstein Distance)1)를 활용해 서로 다른 모달리티 모델 간의 정보 거리를 측정하고, 특정 모달리티의 표현이 다른 모달리티 학습을 촉진할 수 있음을 이론적으로 증명했다. 이를 실험적으로 검증하기 위해 다양한 모달리티 조합에서 테스트를 진행했다. 먼저, 언어 모델이 이미지 모델의 학습을 도울 수 있는지 확인했다. 실험에서는 이미지를 설명함에 있어서 충분하지 않은 단순한 텍스트 프롬프트를 제공했음에도 불구하고 이미지 모델의 성능이 향상됨을 확인했다. 또한, 이미지-오디오, 언어-오디오 형태로 정렬되지 않은 데이터를 활용하더라도 각 모델들이 서로를 도울 수 있는지도 실험했다. 결과적으로 모든 조합에서 기존 단일 모달리티 학습보다 높은 성능이 기록되었다. 3.기대효과 이번 연구는 멀티모달 AI 학습의 새로운 가능성을 열었다는 점에서 의미가 크다. 기존 방식과 달리, 고품질의 정렬된 데이터 없이도 서로 다른 모달리티 모델 간 학습을 촉진할 수 있음을 입증했기 때문이다. 이를 통해 데이터 구축 비용을 절감할 수 있으며, 정렬된 데이터 확보가 어려운 분야에서도 멀티모달 학습을 적용할 수 있는 길이 열렸다. 또한, 단일 모달리티 모델을 다른 모달리티 학습에 활용할 수 있어 AI 모델의 학습 효율이 향상될 것으로 기대된다. 예를 들어, 자율주행 시스템에서는 카메라 데이터만으로도 라이다 센서 데이터를 보완해 학습할 수 있으며, 의료 AI에서는 영상 데이터와 환자의 병력 데이터를 결합해 더 정밀한 진단이 가능해진다.
|
|
[붙임] 용어설명 |
|
1.와서스테인 거리 (Wasserstein Distance) 두 개의 확률 분포 간 거리 또는 유사성 정도를 측정하는 수학적 지표로, 인공지능에서는 주로 모델이 입력 데이터를 어떻게 이해했는지를 나타내는 '잠재 표현 벡터(latent representation vector)'들의 분포를 비교할 때 사용된다. 즉, 서로 다른 데이터(예: 이미지와 텍스트)를 AI가 학습했을 때, 그 안에서 형성된 의미 공간의 차이를 수치로 계산해주는 도구다. 이 거리가 가까울수록, AI는 두 데이터를 비슷한 의미로 해석하고 있다는 뜻이며, 멀티모달 모델의 성능을 평가하거나 개선 방향을 찾는 데 중요한 지표로 활용된다. |
|
[붙임] 그림설명 |
|
그림 1. 본 연구에서 선보인 synergestic multimodal learning 알고리즘. 한 모달리티를 학습할 때 (예: 이미지 모달리티, 빨간색), 다른 모달리티 (예: 언어 모달리티, 회색)의 도움을 받아 학습을 진행할 시에, 두 모달리티의 정보를 모두 포함하는 학습(초록색)이 가능하다. 이를 통해, 이를 통해 모든 모달리티의 특성을 잘 반영하는 방향(검정색)으로 학습할 수 있다.
그림 2. 본 연구 결과 도식화 (t-SNE 도식화) (왼쪽부터) 첫번째) 오디오–언어, 두번째) 언어–오디오, 세번째) 오디오–이미지, 네번째) 비전–오디오 조합으로 학습한 결과. 그림 1에서 이론적으로 가정(hypothesize)한 결과와 유사한 결과가 도출됐다.
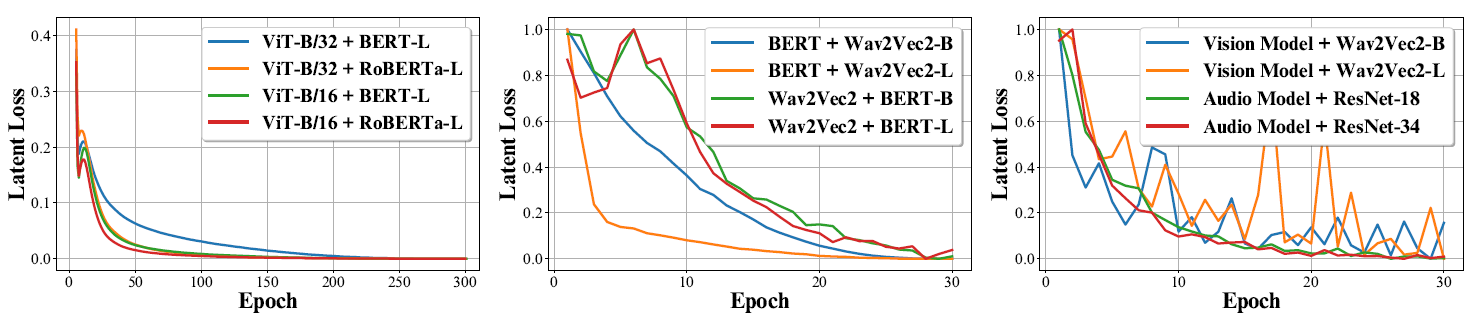
그림 3. 각 실험 세팅 별 손실함수 결과 그림 1과 그림 2에 해당하는 학습하는 모달리티와 도와주는 모달리티 간 표현 벡터의 거리를 좁혀주는 손실함수(Mean Squared Error)가 수렴하는 형태를 보인다. 즉, 학습하는 모달리티의 데이터와 도와주는 모달리티의 데이터 간 서로 정렬되지 않더라도 학습이 원활하게 이뤄지고 성능이 올라가는 결과를 보여준다. |
|
|
UNIST 홍보팀 news@unist.ac.kr TEL : 052)217-1230FAX : 052)217-1229 |




![[연구그림] 본 연구에서 제안된 데이터정렬 없는 멀티모달 학습 알고리즘](https://news.unist.ac.kr/kor/wp-content/uploads/2025/05/연구그림-본-연구에서-제안된-데이터정렬-없는-멀티모달-학습-알고리즘.png)