|
|
|
|
|
AI의 핵심 기술은 새로운 정보를 학습하면서도 기존 지식을 유지하는 것이다. 사람도 새로운 것을 배우면서 기존 경험을 잊지 않듯, AI도 같은 기능을 구현하는 것이 중요하다. UNIST(총장 이용훈) 인공지능대학원 백승렬 교수팀이 AI가 기존 지식을 유지하면서도 새로운 정보를 학습할 수 있는 'SDDGR(Stability Diffusion-based Deep Generative Replay)' 기술을 개발했다. 'SDDGR' 기술은 스마트 가전 제품, 로봇 공학, 의료 분야 등 일상생활에 밀접한 영역에서 AI의 정확한 인식을 가능하게 한다. 특히 자율 주행 자동차가 도로 위의 다양한 물체를 인식하고 안전하게 운행하는 데 큰 도움이 된다. 보안 시스템에 적용하면 침입자를 정확하게 감지해 경고 알람을 즉각 보낼 수 있다. 기존에 개발된 '클래스 증분 학습(CIL)' 기술은 이미지 안의 여러 객체를 인식하고 분류하는 데 한계가 있었다. 이를 해결하기 위해 'SDDGR' 기술이 등장했다. 고품질 이미지를 만들어 이전에 배운 것들을 잘 기억하게 해준다. 반복적인 과정을 통해 이미지의 질을 더 높이며, 기존 지식을 효과적으로 유지할 수 있다. 새로운 데이터를 학습할 때도 성능을 높이는 방법을 사용해 더욱 정확하게 배우는 것이다. 경제적 효율성도 뛰어나다. 기존 데이터를 반복 사용하지 않아 광범위한 데이터를 저장하고 처리하는 비용을 절감할 수 있다. 기업들에게 큰 경제적 이익을 줄 것으로 기대된다. 백승렬 교수는 “SDDGR 모델이 다양한 산업 분야에서 지속적인 객체 탐지의 정확성을 높이는 데 큰 도움이 될 것”이라고 말했다. 제1저자 김준수 연구원은 “SDDGR 기술이 다양한 응용 분야에서 실질적인 효과가 있음을 보여주었다”며, “기업들이 더 적은 비용과 시간으로 더 나은 인공지능 모델을 개발하는 데 기여할 수 있을 것”이라고 언급했다. 이번 연구 결과는 세계적 컴퓨터 비전 학술대회인 CVPR 2024에서 6월 21일 발표될 예정이며, 과학기술정보통신부(MSIT), 한국연구재단(NRF), 정보통신기획평가원(IITP), 해양수산과학기술진흥원(KIMST), LG전자, CJ AI센터의 지원을 받아 수행됐다. (논문명: SDDGR: Stable Diffusion-based Deep Generative Replay for Class Incremental Object Detection) |
|
|
|
[붙임] 연구결과 개요, 용어설명, 그림설명 |
[붙임. 연구결과 개요]1. 연구배경현대 인공지능 기술의 중요한 도전 과제 중 하나는 새로운 정보를 학습하면서도 기존에 습득한 지식을 잃지 않는 것입니다. 이는 인간이 새로운 지식을 배우면서도 기존의 경험과 지식을 유지하는 것과 유사한 방식으로, 인공지능 시스템에서도 동일한 기능을 구현하는 것을 목표로 합니다. 이러한 문제를 해결하기 위해 개발된 기술이 바로 클래스 증분 학습(CIL: Class Incremental Learning)입니다. 클래스 증분 학습은 새로운 클래스를 지속적으로 학습하면서도 이전에 학습한 클래스에 대한 정보를 유지하는 기술입니다. 그러나 이 기술을 객체 탐지(Class Incremental Object Detection, CIOD)에 적용하는 데는 몇 가지 어려움이 따릅니다. 객체 탐지는 이미지 내의 여러 객체를 인식하고 분류하는 작업으로, 다중 라벨이 포함된 복잡한 장면에서의 학습이 필요합니다. 기존의 CIL 기술은 주로 단일 라벨 이미지에서의 분류 작업에 중점을 두었기 때문에, 이러한 복잡한 장면에서의 객체 탐지에는 한계가 있었습니다. 이러한 문제를 해결하기 위해 UNIST 연구팀은 새로운 접근 방식을 제안했습니다. SDDGR(Stability Diffusion-based Deep Generative Replay) 기술은 사전 훈련된 텍스트-이미지 확산 네트워크를 활용하여 현실적이고 다양한 합성 이미지를 생성합니다. 이를 통해 새로운 클래스를 학습하는 동안에도 이전에 학습한 객체들을 잊지 않고 유지할 수 있습니다. 특히, 반복적인 정제 전략을 통해 생성된 이미지의 품질을 높이고, L2 지식 증류 기법과 의사 라벨링 기법을 통해 이전 지식을 효과적으로 유지하는 방법을 도입했습니다. 이 기술은 자율 주행 자동차, 보안 시스템, 로봇 공학 등 다양한 분야에서 활용될 수 있으며, 객체 탐지의 정확성을 크게 향상시킬 수 있습니다. 예를 들어, 자율 주행 자동차는 도로 위의 다양한 물체를 인식하고 안전하게 운행할 수 있으며, 보안 시스템은 침입자를 정확하게 감지하고 경고를 발할 수 있습니다. 이러한 응용 가능성은 SDDGR 기술이 실생활에서 얼마나 유용하게 활용될 수 있는지를 잘 보여줍니다. 2. 연구내용SDDGR 기술은 사전 훈련된 텍스트-이미지 확산 네트워크를 사용하여 현실적이고 다양한 합성 이미지를 생성합니다. 이를 통해 새로운 클래스를 학습하는 동안에도 이전에 학습한 객체들을 잊지 않고 유지할 수 있습니다. 이 기술의 주요 특징은 다음과 같습니다: 3. 기대효과SDDGR 기술은 다양한 분야에서 혁신적인 변화를 가져올 것입니다. 자율 주행, 보안, 로봇 공학 등 다양한 분야에서 객체 탐지의 정확성을 높여 줄 것으로 기대됩니다. 예를 들어, 자율 주행 자동차는 도로 상황을 보다 정확하게 인식하여 안전성을 크게 향상시킬 수 있습니다. 보안 시스템에서는 실시간으로 침입자를 감지하고 대응하는 능력을 향상시킬 수 있습니다. 이러한 응용 가능성은 SDDGR 기술이 실생활에서 얼마나 유용하게 활용될 수 있는지를 잘 보여줍니다. |
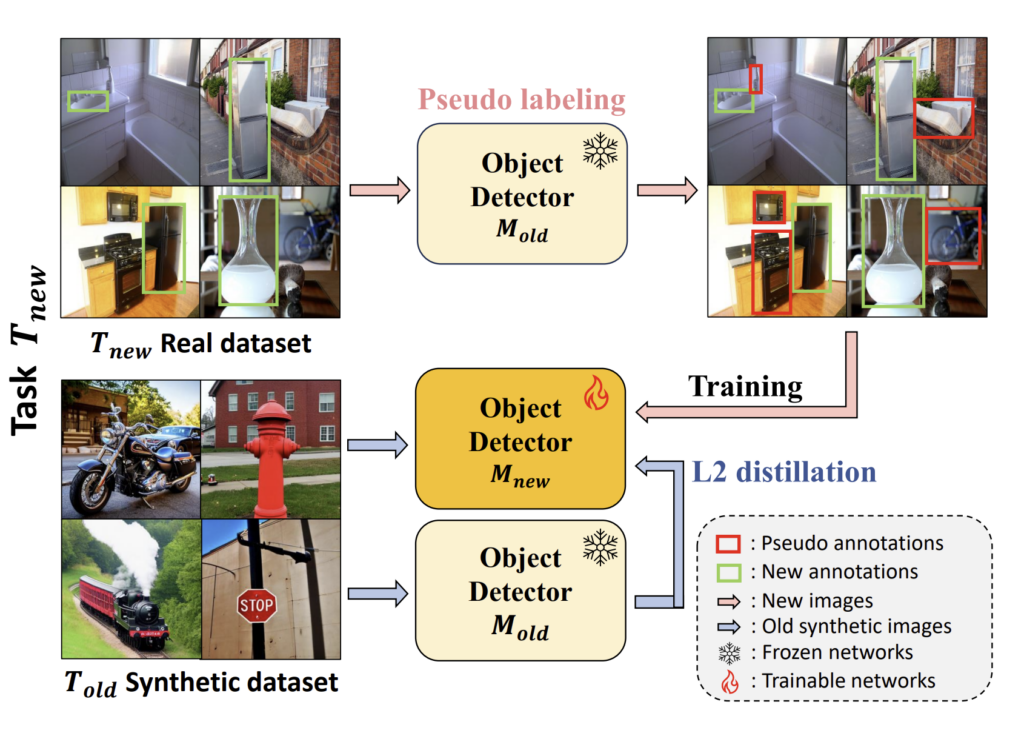
[붙임. 용어설명]1. 클래스 증분 학습 (Class Incremental Learning, CIL)새로운 클래스를 학습하면서도 이전에 학습한 클래스에 대한 정보를 유지하는 기술. 인공지능 모델이 지속적으로 학습할 수 있도록 돕는 방법 중 하나입니다. 2. 객체 탐지 (Object Detection)이미지 내의 여러 객체를 인식하고 분류하는 작업. 객체 탐지는 자율 주행 자동차, 보안 시스템 등 다양한 응용 분야에서 중요한 역할을 합니다. 3. 의사 라벨링 (Pseudo Labeling)기존 모델이 새로운 데이터에 대한 예측을 통해 라벨을 생성하는 과정. 새로운 데이터셋에 대해 기존 지식을 활용하여 라벨을 부여하는 방법입니다. 4. 지식 증류 (Knowledge Distillation)새로운 모델이 기존 모델의 지식을 상실하지 않도록 도와주는 기술. L2 지식 증류(L2 Distillation)는 이전 모델의 지식을 새로운 모델에 전달하여 학습 성능을 유지하는 방법입니다. 5. Stable Diffusion텍스트-이미지 확산 네트워크를 활용하여 현실적이고 다양한 합성 이미지를 생성하는 기술. 이 기술은 SDDGR 모델에서 고품질의 합성 이미지를 생성하는 데 사용됩니다. 6. 반복적인 정제 전략 (Iterative Refinement Strategy)생성된 이미지의 품질을 높이기 위해 반복적인 정제 과정을 거치는 방법. 이를 통해 더욱 정밀한 객체 탐지가 가능하게 됩니다. 7. L2 지식 증류 (L2 Distillation)새로운 모델이 기존 모델의 지식을 상실하지 않도록 돕는 지식 증류 기법의 하나. L2 정규화를 통해 기존 모델의 지식을 효과적으로 유지합니다. 8. Task T_new / Task T_old새로운 실제 데이터셋. 새로운 객체들이 포함된 데이터셋을 의미합니다. / 이전의 합성 데이터셋. 기존 모델이 학습한 객체들이 포함된 데이터셋을 의미합니다. 9. New Object Detector M_new / Old Object Detector M_old새로운 객체 탐지 모델. 이전에 학습한 모델에 새로운 데이터셋을 학습하여 객체를 탐지할 모델입니다. / 기존 객체 탐지 모델. 이전에 학습한 데이터를 바탕으로 객체를 탐지하는 모델입니다. |
[붙임. 그림설명]
SDDGR(안정적 확산 기반 딥 생성 재생) 모델의 작동 과정이 그림은 SDDGR 모델의 작동 과정을 시각적으로 설명한 것입니다. SDDGR 모델은 새로운 데이터를 학습하면서도 기존 데이터를 잊지 않는 기술입니다. 첫 번째 행의 왼쪽에 있는 이미지들은 새로운 실제 데이터셋 (Task T_new)을 나타냅니다. 여기에는 새로운 객체들이 포함되어 있습니다. 이 새로운 데이터셋을 이용하여 기존 객체 탐지 모델인 M_old을 사용해 의사 라벨링(Pseudo labeling)을 수행합니다. 이는 기존 모델이 새로운 데이터에 대한 예측을 통해 라벨을 생성하는 과정으로, 새로운 객체와 함께 이전 객체들도 포함된 이미지에 의사 라벨을 추가하는 것을 의미합니다. 의사 라벨링이 완료된 후, 새로운 객체 탐지 모델인 M_new을 훈련시킵니다. 이 모델은 새로운 데이터셋을 이용하여 학습하며, 동시에 L2 지식 증류(L2 distillation)를 통해 기존 모델 M_old의 지식을 유지합니다. L2 지식 증류는 새로운 모델이 이전 모델의 지식을 상실하지 않도록 도와주는 기술입니다. 두 번째 행의 왼쪽에 있는 이미지들은 이전의 합성 데이터셋(Task T_old)을 나타냅니다. 이는 기존 모델이 학습한 객체들이 포함된 데이터입니다. 새로운 모델 M_new과 기존 모델 M_old은 이 합성 데이터셋을 이용하여 학습하고, 이를 통해 새로운 데이터와 이전 데이터를 모두 잘 인식할 수 있게 됩니다. 빨간색 사각형은 의사 라벨링(Pseudo annotations)을 나타내며, 이는 기존 모델이 새로운 데이터에서 예측한 라벨입니다. 녹색 사각형은 새로운 라벨(New annotations)을 나타내며, 새로운 데이터셋에 실제로 부여된 라벨입니다. 파란색 화살표는 L2 지식 증류 과정을 나타내며, 새로운 모델이 기존 모델의 지식을 유지하면서 학습하는 것을 의미합니다. 이 그림은 SDDGR 모델이 새로운 데이터를 학습하면서도 기존의 지식을 잊지 않고 유지하는 과정을 시각적으로 잘 설명하고 있습니다. |
|
|
UNIST 홍보팀 news@unist.ac.kr TEL : 052)217-1230FAX : 052)217-1229 |





![[연구자 사진] 김준수 연구원](https://news.unist.ac.kr/kor/wp-content/uploads/2014/11/press_20141125_03.jpg)
![[연구그림] SDDGR(안정적 확산 기반 딥 생성 재생) 모델의 작동 과정](https://news.unist.ac.kr/kor/wp-content/uploads/2014/11/press03_20141125.jpg)