|
|
|
|
|
우리의 일상과 산업 전반에 깊이 스며든 3D 재구성 기술이 한층 더 발전했다. UNIST 연구팀이 개발한 정밀 3D 모델링 기술은 문화재 복원에 새로운 가능성을 열어줄 전망이다. UNIST(총장 이용훈) 인공지능대학원의 주경돈 교수팀은 물체의 형상을 세밀하게 재구성하는 DITTO(Dual and Integrated Latent Topologies) 기술을 개발했다. 점을 찍어 형태를 그리는 점구름 방식과 상자 안에 물체를 그리는 격자 방식을 합친 것이다. DITTO 기술은 점구름 데이터를 격자 형태로 변환하고, 두 가지 데이터를 동시에 활용해 중요한 정보를 추출한다. DSPT(Dynamic Sparse Point Transformer) 분석 도구를 통해 점구름 데이터를 정밀하게 분석하며, 복잡하고 얇은 물체도 정밀하게 모델링할 수 있는 중요한 특징을 뽑아낸다. 의학, 로봇공학, 가상현실 등 다양한 산업 분야에서 3D 모델링의 정확도를 크게 높일 가능성을 보인 것이다. 추출된 데이터를 바탕으로 IID(Integrated Implicit Decoder)는 3D 공간의 특정 위치가 물체 내부인지 외부인지를 예측한다. 이를 통해 기존 기술보다 더 정확하고 세밀한 3D 재구성이 가능해졌다. 정확도가 높아진 3D 모델링 기술은 손상되거나 파손된 문화재를 정밀하게 복원할 수도 있다. 정교한 형상과 질감을 정확하게 표현해 원형을 재현하는 데 있어 중요한 도구가 될 것으로 기대된다. 주경돈 교수는 "이번 연구는 3D 재구성의 정확성을 높이는 것을 넘어, 3D 데이터를 사용하는 다양한기술에 새로운 방법을 제시한다"며 "메타버스 및 CAD/CAE 등 콘텐츠와 산업 전반에 큰 도움이 될 것"이라고 밝혔다. 제1저자인 심재혁 연구원은 “이 기술은 3D 데이터를 표현하는 새로운 방법이 될 수 있어 기술 발전 가능성이 크다”며 “다양한 학계 및 산업계와의 협업이 기술 발전에 중요한 역할을 할 것"이라고 덧붙였다. (논문명: DITTO: Dual and Integrated Latent Topologies for Implicit 3D Reconstruction DITTO, 암묵적 3D 재구성을 위한 듀얼 및 통합 잠재 토폴로지) |
|
|
|
[붙임] 연구결과 개요, 용어설명, 그림설명 |
[붙임. 연구결과 개요]1. 연구배경3D 재구성 기술은 3차원 공간에서 물체의 형상을 재현하는 기술입니다. 이 기술은 주어진 포인트 클라우드(3D 공간에서 측정된 점들의 집합)가 주어졌을 때 특정 위치에서 해당 위치가 물체의 내부인지 외부인지를 예측하는 방식을 사용합니다. 기존의 3D 재구성 기술들은 벡터, 그리드, 포인트 클라우드 등의 방법을 사용하며 각기 다른 장단점을 가지고 있습니다. 벡터 방식은 단순한 형태로 데이터를 표현할 수 있지만, 큰 장면이나 복잡한 구조를 처리하는 데 한계가 있습니다. 그리드 방식은 3D 공간을 격자 모양으로 나눠서 데이터를 저장하는 방식으로, 비교적 정확하게 3D 형상을 재현할 수 있지만, 해상도에 한계가 있어서 세밀한 부분을 표현하는 데 어려움이 있습니다. 포인트 클라우드 방식은 3D 공간에서 측정된 점들의 집합을 그대로 사용하는 방식으로, 세밀한 부분을 잘 표현할 수 있지만, 노이즈(데이터의 불필요한 잡음)에 민감하여 안정적인 결과를 얻기 어렵습니다. 이러한 각 방식의 약점을 보완하고 장점을 결합하기 위해 새로운 접근 방식이 필요합니다. 이를 해결하기 위해 DITTO가 제안되었습니다. 2. 연구내용이번 연구에서는 위의 두 가지 방식의 장점을 모두 결합한 새로운 3D 재구성 기술인 DITTO를 제안합니다. DITTO는 두 가지 잠재 변수를 동시에 사용하는 듀얼 잠재 인코더(Dual Latent Encoder)와 통합 암묵 디코더(Integrated Implicit Decoder, IID)로 구성된 구조입니다. 듀얼 잠재 인코더는 포인트 클라우드로부터 특징을 추출하여 포인트 형태의 잠재 변수를 추출하고, 이를 그리드 형태로 투사(projection)하여 그리드 잠재 변수를 얻습니다. Dynamic Sparse Point Transformer(DSPT)는 포인트 클라우드 데이터로부터 더 정밀하게 정보를 추출해내는 딥러닝 모듈로서, 넓은 범위의 정보를 활용하여 점 데이터를 학습함으로써 중요한 특징을 추출합니다. 통합 암묵 디코더(IID)는 듀얼 잠재 인코더에서 추출된 그리드와 포인트 잠재 변수를 입력으로 받아 3D 공간의 임의의 위치에서 해당 위치가 3D 객체 내부인지 외부인지를 예측하는 점유율(occupancy) 값을 계산합니다. DITTO는 이러한 방식을 통해 기존 기술보다 더 정확하고 세밀한 3D 재구성을 실현할 수 있습니다. 3. 기대효과DITTO는 3D 재구성 성능을 크게 향상시킨 성능을 보여주었습니다. 특히, DITTO는 얇고 세밀한 구조에서도 탁월한 성과를 보여줍니다. 예를 들어, 매우 얇은 물체나 복잡한 모양의 물체를 더욱 정확하게 모델링할 수 있습니다. 이는 의학(예: 3D 프린팅된 장기), 로봇공학(예: 정밀 로봇 부품), 가상현실(예: 더 현실적인 가상 환경) 등 다양한 산업 분야에서 3D 모델링의 정확도를 높이고 복잡한 구조를 더욱 정확하게 재현하는 데 큰 도움이 될 수 있습니다. |
[붙임. 용어설명]1. 암묵적 3D 재구성 (Implicit 3D Reconstruction)주어진 좌표를 기반으로 객체의 표면을 추정하는 기술로, 객체의 외곽선이나 형상을 계산하여 3차원 모델을 만듭니다. 이는 점유율 필드나 서명 거리 필드와 같은 암묵적 값을 이용해 이루어집니다. 2. 점군 데이터 (Point Cloud Data)3D 공간에서 측정된 여러 점들의 집합으로, 각 점은 3차원 좌표(x, y, z)를 가지며 이를 통해 객체의 형태를 표현합니다. 3. 잠재 변수 (Latent Representation)데이터를 압축하고 요약하여 중요한 특징을 나타내는 변수들로, 벡터, 그리드, 점군 등의 형태로 표현될 수 있습니다. 4. 그리드 잠재 변수 (Grid Latents)3차원 공간을 일정한 격자로 나눈 후 각 격자점에서 데이터를 표현하는 방식으로, 주로 고해상도 3D 재구성에 사용됩니다. 5. 점 잠재 변수 (Point Latents)점군 데이터를 그대로 잠재 변수로 사용하는 방식으로, 입력 점의 세부 정보를 보존하여 정밀한 재구성을 가능하게 합니다. |
[붙임. 그림설명]
그림1. DITTO의 개요DITTO 아키텍처는 제안된 듀얼 잠재 인코더와 통합 암묵 디코더(IID) 모듈로 구성됩니다. 인코더에서 DITTO는 점군 데이터를 받아 얕은 FKAConv 레이어를 사용하여 점 잠재 변수와 그리드 잠재 변수를 생성합니다. 이러한 잠재 변수들은 제안된 DLL로 구성된 U자형 네트워크에서 각각 정제된 점 잠재 변수와 정제된 그리드 잠재 변수로 정제됩니다. IID는 주어진 임의의 쿼리 위치에 대한 점유율을 추정합니다. 메쉬는 정규 그리드 형태로 추정된 점유율에 Marching Cubes 알고리즘을 적용하여 얻을 수 있습니다.
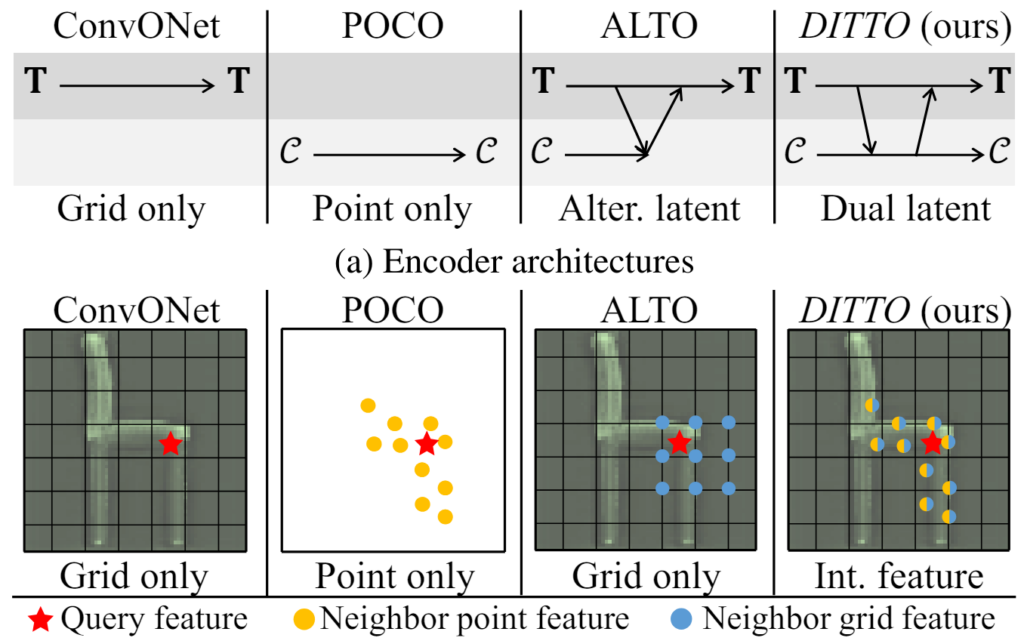
그림2. DITTO 및 기존 방법론의 개념적 비교우리는 잠재 표현 측면에서 암시적 3D 재구성 방법의 개념을 비교합니다: (a) 인코더와 (b) 디코더. (b)에서는 초록색 의자의 이미지가 그리드 특징을 나타냅니다.
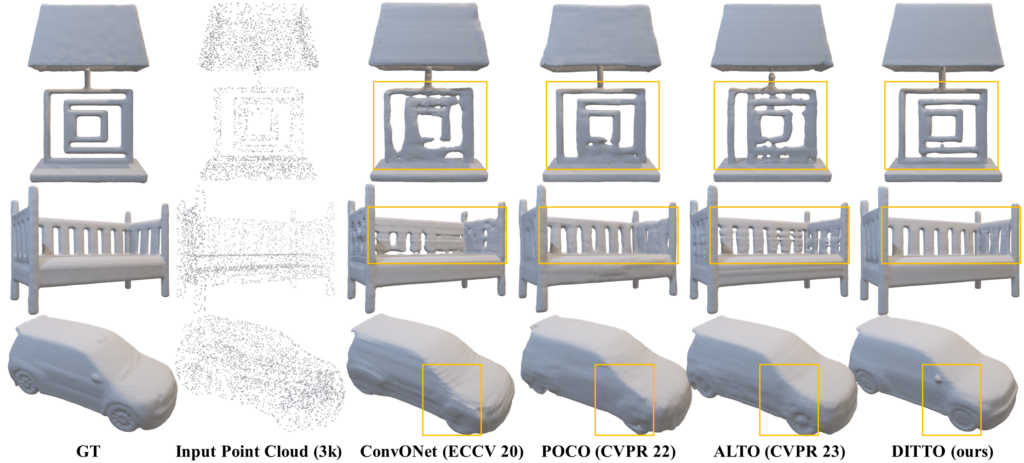
그림3. ShapeNet에서 3천 개의 입력 점으로 객체 수준 3D 재구성 비교DITTO는 램프와 벤치의 정교한 디테일로 얇은 구조물을 재구성하는 데 탁월함을 보여줍니다. 특히, DITTO는 사이드 미러와 자동차 바퀴의 세부 사항을 정확하게 포착하는 유일한 방법입니다.
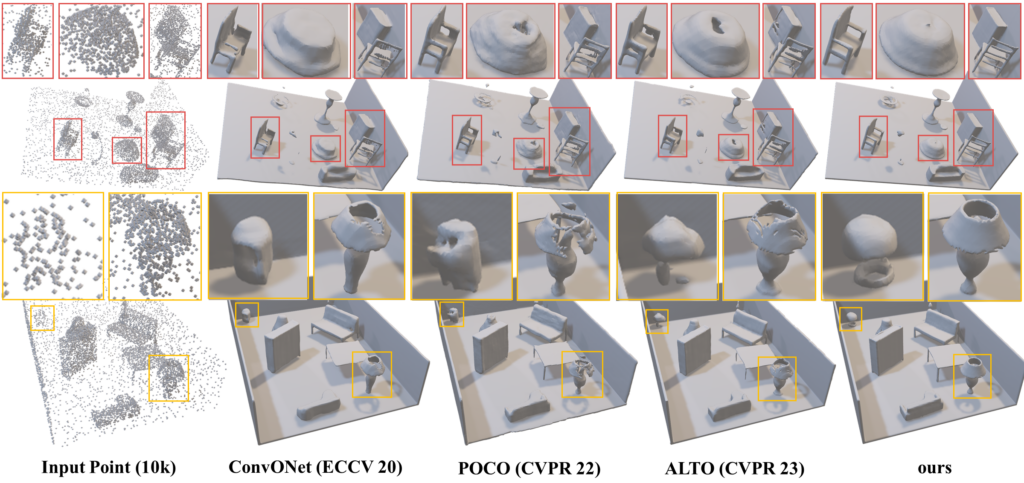
그림4. Synthetic Rooms 데이터셋에서 장면 수준 재구성 성능 평가그리드 기반 방법인 ConvONet의 결과는 얇은 구조에서 구멍이 적고 비교적 안정적이지만, 디테일한 형상의 복원력이 부족합니다 (빨간 상자 안의 램프 참조). 반면, 포인트 기반 방법인 POCO는 더 나은 디테일 복원을 보여주지만, 종종 구멍과 아티팩트가 발생하여 안정성이 떨어집니다 (노란 상자 안의 램프 및 의자 참조). ALTO는 두 가지 잠재 표현을 모두 사용하여 ConvONet보다 더 나은 세부 사항을, POCO보다 더 나은 안정성을 제공하나, ConvONet보다 안정성이 떨어지고 POCO보다 세부 사항이 부족한 모습을 보입니다. 이전 접근 방식과 달리, DITTO는 뛰어난 안정성과 세부 사항을 모두 검증합니다. 이 결과는 두 가지 잠재 표현의 통합에서 시너지를 얻는다는 것을 보여줍니다. |
|
|
UNIST 홍보팀 news@unist.ac.kr TEL : 052)217-1230FAX : 052)217-1229 |




![[연구그림2] DITTO 및 기존 방법론의 개념적 비교](https://news.unist.ac.kr/kor/wp-content/uploads/2014/11/press_20141125_03.jpg)
![[연구그림3] ShapeNet에서 3천 개의 입력 점으로 객체 수준 3D 재구성 비교](https://news.unist.ac.kr/kor/wp-content/uploads/2014/11/press03_20141125.jpg)
![[연구그림4] Synthetic Rooms 데이터셋에서 장면 수준 재구성 성능 평가](https://news.unist.ac.kr/kor/wp-content/uploads/2024/06/연구그림4-Synthetic-Rooms-데이터셋에서-장면-수준-재구성-성능-평가-151x71.png)