|
|
|
|
|
AI 발전과 함께 사용자 개인정보 침해 문제가 심각해지고 있는 가운데, 이를 해결할 연합학습 핵심기술이 등장했다. IT 기업들이 주목하는 기기 내(On-Device) AI 학습에 도움이 될 전망이다. UNIST(총장 박종래) 인공지능대학원 윤성환 교수팀은 개인정보를 보호하면서도 AI 성능을 높일 수 있는 FedGF(Federated Learning for Global Flatness) 기술을 개발했다. 사용자 데이터 유출 문제를 해결할 것으로 기대된다. 연구팀은 다양한 사용자 데이터 분포 상황에서도 일관되게 높은 성능을 내는 방법을 개발했다. 기존 기술은 사용자 데이터 분포와 유사한 환경에서만 우수한 성능을 보였지만, 다른 환경에서는 성능이 낮았다. 연합학습은 사용자 기기에서 딥러닝 모델을 학습해 개인정보를 보호하지만, 데이터 차이로 성능에 한계가 있다. FedGF는 데이터를 중앙 서버로 보내지 않고, 각 기기에서 학습된 모델을 통해 최적화된 모델을 만들어 높은 정확도를 보였다. FedGF는 효율성도 뛰어났다. 기존 방법보다 적은 통신자원으로 완전한 학습이 가능하다. Wi-Fi와 같은 무선통신을 사용하는 모바일 장치들에 특히 유리하다. 윤성환 교수는 “연합학습 기술은 AI 개인정보 침해 문제 해결의 핵심적인 발판이 될 것이다”며, “IT 빅테크 기업들의 개인정보 문제와 분산 데이터 이질성 극복에 큰 도움이 될 것”이라고 밝혔다. 제1저자 이태환 연구원은 “FedGF 기술로 기업은 개인정보 침해 없이 높은 성능의 AI 모델을 얻을 수 있어, IT, 의료, 자율주행 등 다양한 분야에 주요 역할을 할 것”이라고 덧붙였다. 연구 결과는 세계적 국제학술대회 ICML(International Conference on Machine Learning)에 7월 20일 온라인 게재됐다. 연구는 과학기술정보통신부 지원 정보보호 국제공동연구 및 정보통신방송혁신인재양성사업을 통해 수행됐다. (논문명: Rethinking the Flat Minima Searching in Federated Learning) |
|
|
|
[붙임] 연구결과 개요, 용어설명, 그림설명 |
[연구결과 개요]1. 연구배경현재 딥러닝은 많은 분야에서 사용되고 있으며, 많은 편리함을 가져오고 있다. 딥러닝 모델을 학습하기 위해 데이터가 필수적이며, 데이터를 중앙 서버에 모아 학습을 진행한다. 하지만, 이 데이터를 모으며 사용자들이 가진 데이터를 활용하는데, 이때 사용자의 개인정보를 침해할 우려가 있다. 이 개인정보 침해 문제를 해결하기 위해 연합학습(Federated Learning)기술이 등장하였다. 연합학습은 사용자가 가진 데이터를 중앙 서버로 보내는 것이 아닌, 사용자가 본인이 가진 데이터를 활용해 딥러닝 모델을 학습하고, 학습된 모델을 중앙 서버에 보내는 것이다. 이때, 중앙 서버는 각 사용자가 가진 데이터를 확인할 수 없기 때문에, 사용자의 Data Privacy를 지킬 수 있다. 이러한 연합학습이 다양한 분야에 사용되고 있지만, 실제 환경에서는 각 사용자의 데이터 이질성(Heterogeneity, 각 사용자가 가진 데이터들이 다른 정도)으로 인해 딥러닝 모델 성능에 악영향을 주고 있다. 2. 연구내용본 연구팀은 연합학습에서 사용자가 학습하는 로컬 모델 뿐만 아니라, 글로벌 모델의 일반화 성능을 높일 수 있는 방법을 개발하였다. 먼저 기존 방법은 일반화 성능을 높이는 방법중 하나인 SAM(Sharpness-Aware Minimization)3)를 통해 사용자가 가진 로컬 모델이 완만한(Flat)한 손실함수 형태를 가지도록 하여 일반화 성능을 높인다. 본 연구팀은 데이터의 이질성이 높은 환경에서 로컬 모델의 완만한 최소점(Flat minima)을 찾는 것이 아닌, 글로벌 모델의 손실함수를 완만하게 만들도록 한다. 제안한 알고리즘(FedGF)의 수학적 분석과 이미지 데이터를 활용한 실험을 통해 데이터 이질성 및 사용자의 참여율에 따른 실제 성능을 측정하였다. 결과적으로 FedGF가 찾은 모델이 기존 연구에서 제시한 방법보다 더 완만한 손실함수를 찾았으며, 높은 성능(빠른 수렴속도, 높은 정확도)를 보인다. 3. 기대효과연합학습은 최근 제기된 딥러닝의 개인정보 보호 문제를 해결할 수 있는 방법중 하나이다. 본 연구에서 개발한 알고리즘(FedGF)를 통해 연합학습의 성능 향상을 보였으며, 개인정보 문제를 해결할 수 있기 때문에 개인정보가 민감한 분야인 의료, 금융, 이미지, 언어 관련 분야에 활용될 것으로 기대된다. |
[용어설명]1. 플랫 미니마 (Flat Minima)손실함수가 완만한 곡률을 보이는 최소점 2. 일반화 성능 (Generalization Ability)딥러닝 모델을 학습시킨 데이터 분포가 변했을 때, 모델의 성능이 얼마나 차이나는지 확인할 수 있는 지표. 3. SAM (Sharpness-Aware Minimization)모델의 일반화 성능을 높일 수 있는 알고리즘이며, Sharpness라는 지표를 목적함수 내부에 포함시켜 이론적으로 일반화 성능을 보인 알고리즘. |
[그림설명]
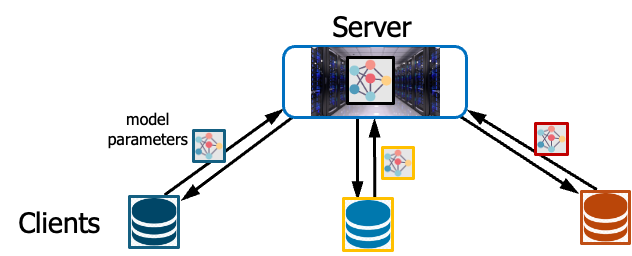
그림1. 연합학습 알고리즘각 사용자는 자신이 가진 데이터를 사용해 모델을 학습하고, 학습된 모델을 서버에 업로드 한다. 서버는 사용자들로부터 받은 모델을 Average하고, 다시 사용자에게 분배한다. 이 과정에서 모든 사용자들은 자신이 가진 데이터를 다른 서버 및 사용자에게 보여주지 않기 때문에 개인정보 침해를 막을 수 있다. 또한, 다른 사용자들이 가진 모델정보를 받기 때문에, 더 많은 데이터로 학습된 모델을 얻을 수 있다.
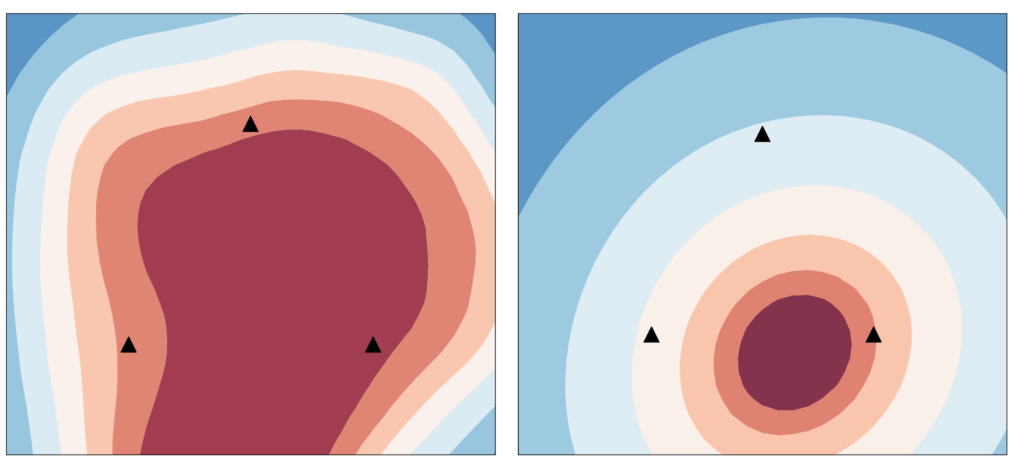
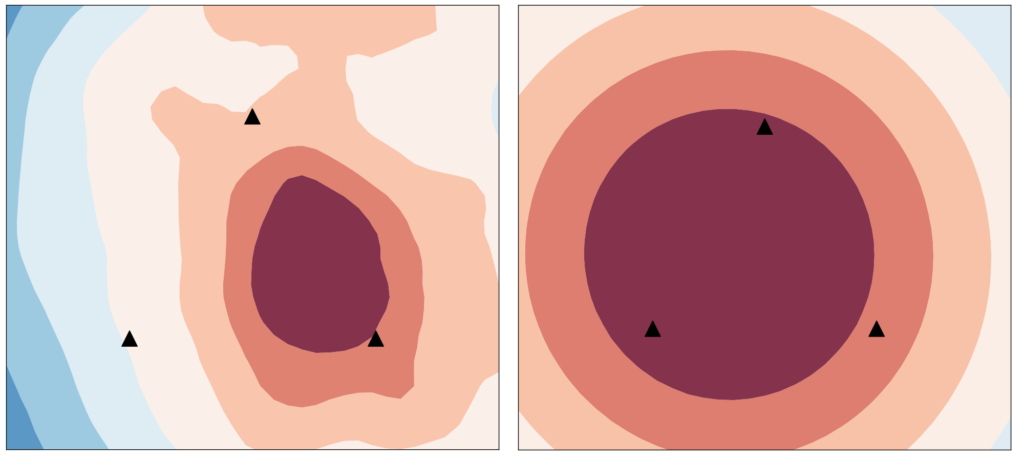
그림2. 기존 연합학습 알고리즘의 문제점좌측) 사용자가 학습한 로컬 모델의 손실함수를 표현하고 있으며, 완만한 손실함수의 위치를 찾은 모습. 우측) 글로벌 모델의 손실함수 그림이며, 좌측 로컬모델의 손실함수보다 더 급격한 경사를 보여준다.
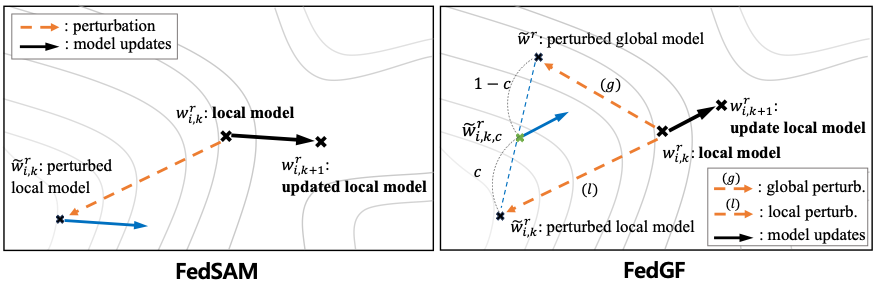
그림3. 기존 방법(좌측)과 제안한 알고리즘(우측)의 비교기존 방법은 오직 사용자가 가진 데이터에 대해 높은 성능을 보이는 모델을 찾는다. 하지만, 제안한 알고리즘 (FedGF)는 자신이 가진 데이터가 아닌 모든 사용자가 가진 데이터에 대해 높은 성능을 보이는 방식으로 작동한다.
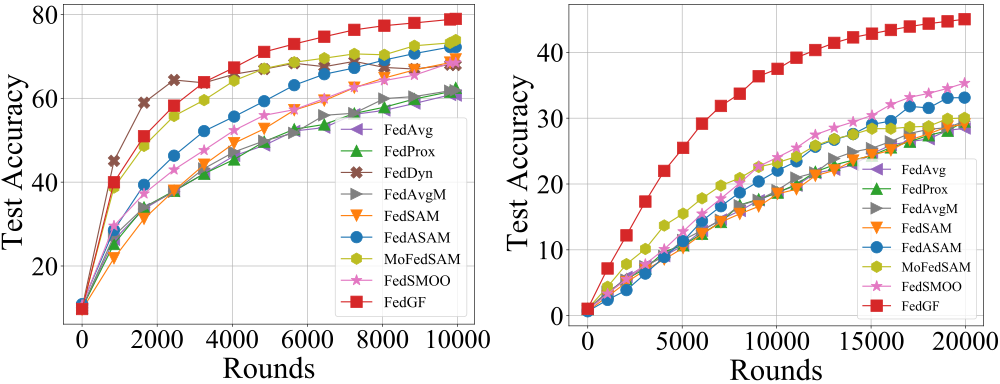
그림4. 제안한 알고리즘의 성능 (FedGF: 빨강색 박스)제안한 알고리즘 FedGF는 이미지 데이터셋 CIFAR-10과 CIFAR-100에서 빠른 수렴속도와 높은 정확도를 보여준다. 그림5. 개발한 알고리즘 (FedGF)의 손실함수좌측) 사용자가 학습한 로컬 모델의 손실함수를 표현하고 있으며, 우측에 있는 글로벌 모델의 손실함수 대비 조금 더 급격한 손실함수의 위치를 찾은 모습. 우측) 글로벌 모델의 손실함수 그림이며 완만한 경사를 보여준다. |
|
|
UNIST 홍보팀 news@unist.ac.kr TEL : 052)217-1230FAX : 052)217-1229 |




![[연구그림1] 연합학습 알고리즘](https://news.unist.ac.kr/kor/wp-content/uploads/2014/11/press_20141125_04.jpg)
![[연구그림2] 기존 연합학습 알고리즘의 문제점](https://news.unist.ac.kr/kor/wp-content/uploads/2014/11/press_20141125_03.jpg)
![[연구그림3] 기존 방법(좌측)과 제안한 알고리즘(우측)의 비교](https://news.unist.ac.kr/kor/wp-content/uploads/2014/11/press03_20141125.jpg)
![[연구진 사진] 위에서부터 윤성환 교수, 이태환 연구원](https://news.unist.ac.kr/kor/wp-content/uploads/2024/08/연구진-사진-위에서부터-윤성환-교수-이태환-연구원-151x125.jpg)