
A research team, affiliated with UNIST has introduced an AI grid diffusion model that generates high-definition videos based on text input while requiring less data and GPU memory.
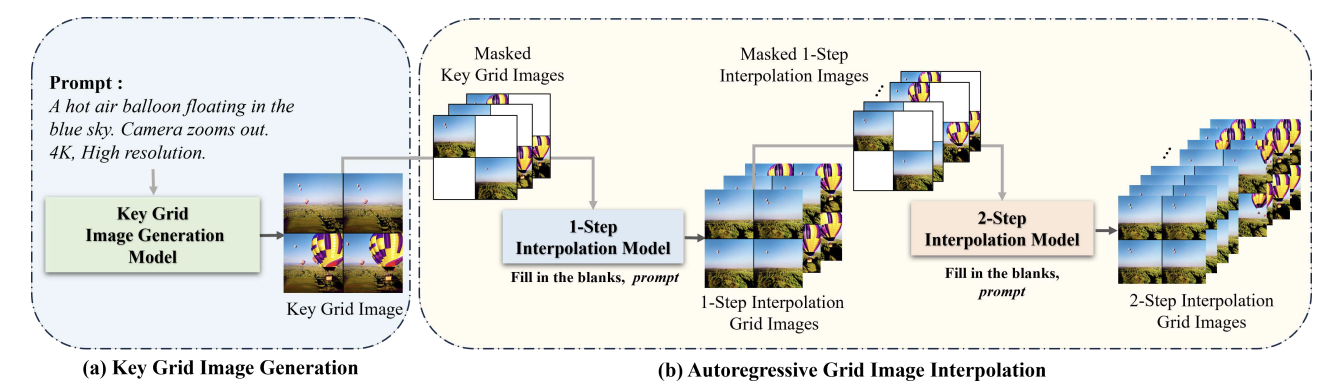
Figure 1. Overview of their approach to generate grid images.
Professor Taehwan Kim and his research team in the Graduate School of Artificial Intelligence at UNIST has developed a “Text to Video” technology that automatically generates high-quality video content from sentence inputs, utilizing only 1% of the data and minimal computational resources.
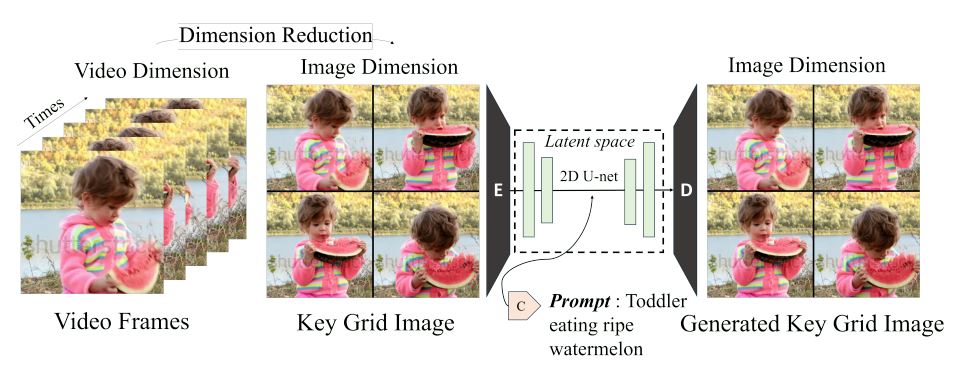 Figure 2. Visualization of key grid image generation model training.
Figure 2. Visualization of key grid image generation model training.
The grid diffusion model produces new videos based on the provided text. By integrating a video generation function into the existing “Text to Image” technology, which converts text into images, the model can yield a diverse array of outputs without necessitating extensive data or high-performance computing systems.
 Figure 3. Visualization of the interpolation model training.
Figure 3. Visualization of the interpolation model training.
The research team creates the video by converting the text into four grid-shaped images. For instance, when the sentence “A puppy runs around in the park” is entered, four images depicting a dog running in the park are generated. These images are arranged in a grid to simulate a single video.
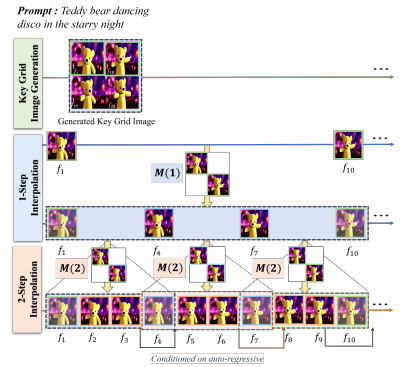 Figure 4. The inference procedure.
Figure 4. The inference procedure.
The research team creates the video by converting the text into four grid-shaped images. For instance, when the sentence “A puppy runs around in the park” is entered, four images depicting a dog running in the park are generated. These images are arranged in a grid to simulate a single video.
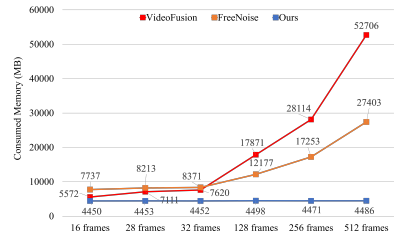 Figure 8. The efficiency comparison of GPU memory usage.
Figure 8. The efficiency comparison of GPU memory usage.
This model can produce lengthy images with minimal data because it learns efficiently. Additionally, it is practical, as existing image modification methodologies can be directly applied to videos. The resolution can also be easily scaled up, indicating its potential for widespread use in various media industries, such as education and entertainment.
“The grid diffusion model demonstrates the potential for competitive AI research, even within small laboratories or companies,” said first author Tegyeong Lee. “AI-generated videos can be utilized in numerous ways across different industries and real-life applications.”
 Figure 7. The result of video manipulation.
Figure 7. The result of video manipulation.
The research findings have been presented at the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024, a global computer vision conference scheduled to take place from June 17 to 21 in Seattle, U.S.A.
Journal Reference
Taegyeong Lee, Soyeong Kwon, Taehwan Kim, “Grid Diffusion Models for Text-to-Video Generation,” CVPR 2024, (2024).









{kind=link}