
A groundbreaking artificial intelligence (AI) technology has been developed that enables autonomous systems to make accurate judgments even in unfamiliar situations. This advancement is expected to enhance the safety and reliability of AI applications, particularly in scenarios such as autonomous vehicles encountering snowy conditions or robots facing sudden changes in the weight of items they are transporting.
A research team, led by Professor Sung Whan Yoon at the Graduate School of Artificial Intelligence at UNIST has developed a reinforcement learning (RL) technique that maintains stable performance without degradation, even amid environmental changes. This significant contribution has led to their paper being selected for oral presentation at the prestigious International Conference on Learning Representations (ICLR), one of the top three AI conferences in the world. Out of 11,672 submissions, only 207 papers—equivalent to less than 2%—were chosen for oral presentation.
Unlike supervised learning, where correct answers are predefined, reinforcement learning learns through trial and error to maximize rewards, ultimately discovering an optimal strategy known as a “policy.” However, traditional RL methods often exhibit a sharp decline in performance when faced with unfamiliar environments.
To address this limitation, the research team proposed a learning method that reduces the sensitivity of cumulative rewards. This strategy flattens the reward surface in the policy parameter space to ensure that changes in cumulative reward values due to variations in actions do not fluctuate excessively. For instance, whereas traditional approaches can significantly penalize an autonomous vehicle for a slight misjudgment in braking on snowy roads, the proposed method maintains consistent performance even with slight policy adjustments.
In experiments involving physical changes, such as friction conditions and weights in real-world robots, the newly developed learning technique achieved an average reward retention rate of 80–90%, showcasing a high level of stability and resilience. In contrast, traditional learning methods revealed significant limitations, with average rewards dropping to below 50% under identical conditions.
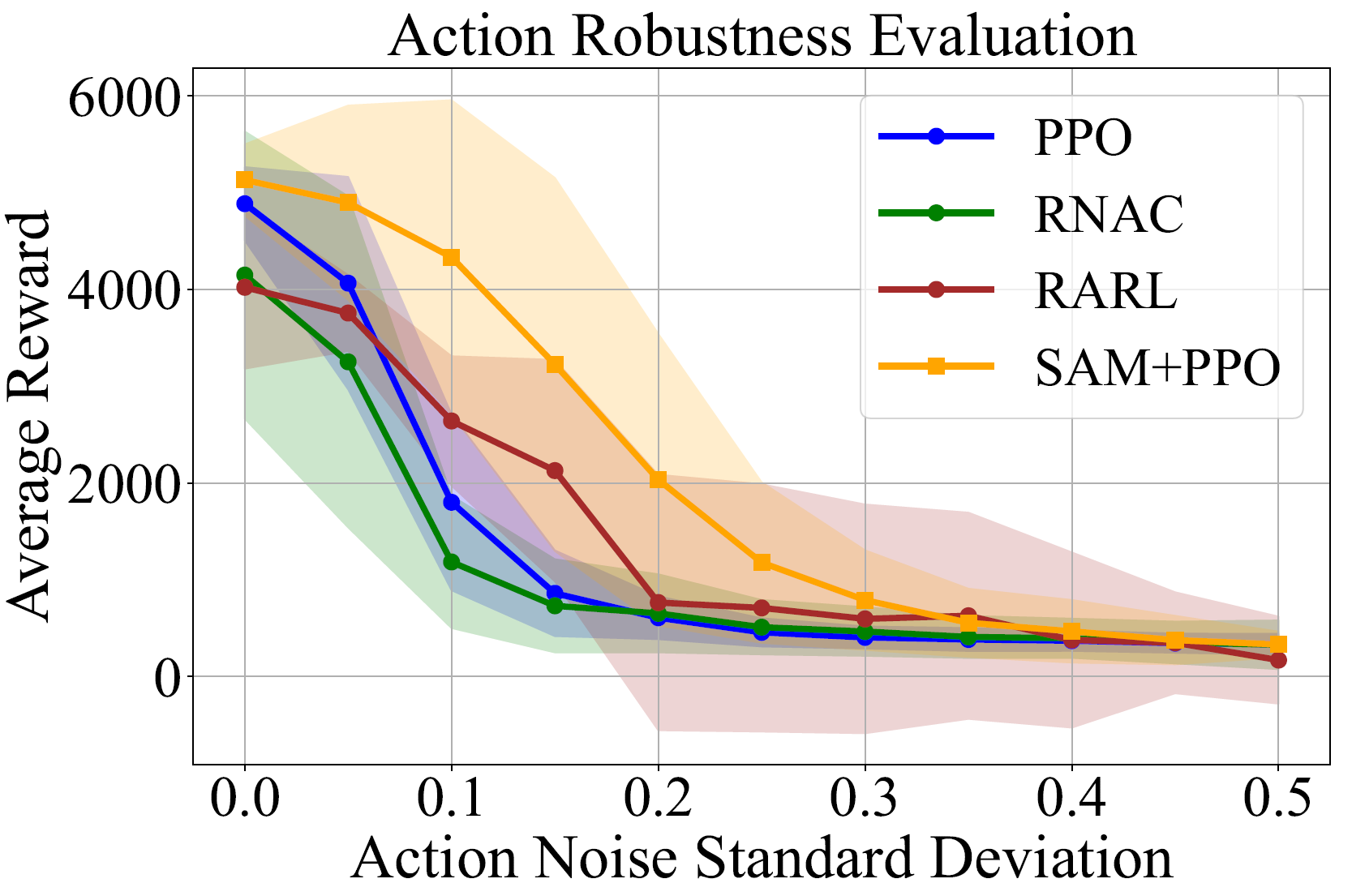 Figure 3: Action robustness evaluation across different environments. The average return is plotted against the action noise standard deviation σa.
Figure 3: Action robustness evaluation across different environments. The average return is plotted against the action noise standard deviation σa.
First author Hyun Kyu Lee explained, “We developed this learning method by borrowing the SAM (Sharpness-Aware Minimization) technique used in supervised learning to lower the sensitivity of cumulative rewards in reinforcement learning.” He further described the approach as “Effective” and “Easy to apply.”
In supervised learning, AI models learn based on a loss function, which assesses the degree of deviation from the correct answers. SAM aims to seek out flat minima to prevent sudden spikes in loss. The research team adapted this concept for reinforcement learning by adjusting the learning trajectory to ensure that cumulative rewards do not fluctuate dramatically.
Professor Yoon expressed hopes that high-performing reinforcement learning models will be employed in robotics and autonomous driving applications that require superior generalization performance.
Meanwhile, the International Conference on Learning Representations (ICLR) is recognized as one of the top three AI conferences alongside ICML and NeurIPS. ICLR 2025 will take place from April 24 to 28 in Singapore, where 3,646 papers were selected from submissions worldwide. The research was conducted with the support of the National Information Society Agency, the National Research Foundation of Korea, and UNIST.
Journal Reference
Hyun Kyu Lee and Sung Whan Yoon, “Flat Reward in Policy Parameter Space Implies Robust Reinforcement Learning,” ICLR 2025, (2025).










{kind=link}