
UNIST 연구팀이 적은 데이터와 GPU 메모리로 텍스트 기반의 고화질 동영상을 생성하는 AI 그리드 확산 모델을 선보였다.
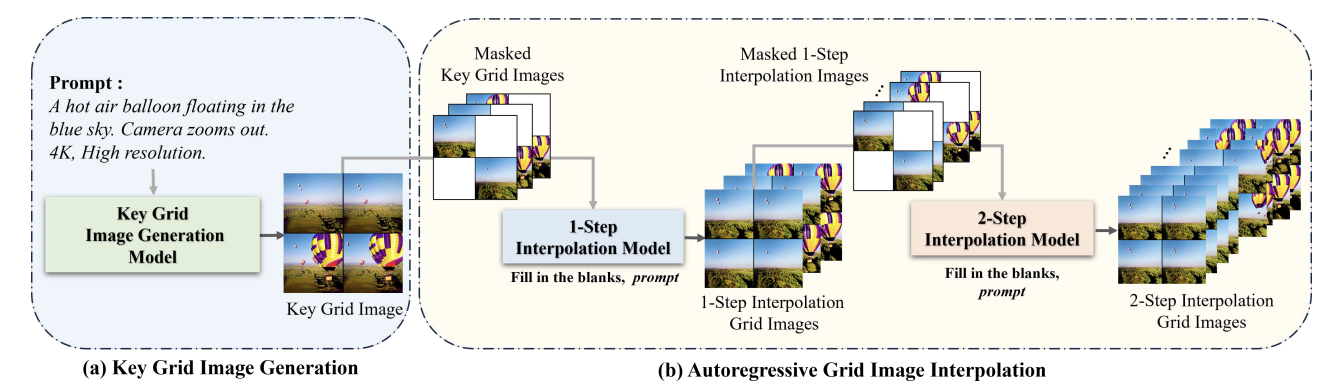
그림1. 그리드 이미지 생성 방법 개요
인공지능대학원 김태환 교수팀이 단 1%의 데이터와 최소한의 컴퓨터 자원만으로 문장 입력을 통해 고품질 영상 콘텐츠를 자동으로 생성하는 ‘Text to Video’ 기술을 개발했다.

그림2. 주요 그리드 이미지 생성 모델 학습의 시각화
그리드 확산 모델은 주어진 텍스트를 기반으로 새로운 동영상을 생성한다. 텍스트를 이미지로 변환하는 기존의 ‘Text to Image’ 기술에 동영상 생성 기능을 추가해 많은 데이터와 고성능 컴퓨터 없이도 다양한 결과물을 만들어낼 수 있다.

그림3. 보간 모델 훈련의 시각화 모델
연구팀은 텍스트에서 4장의 격자 형태의 이미지로 변환해 동영상을 만들었다. “강아지가 공원에서 뛰어논다.”라는 문장을 입력하면, 공원에서 강아지가 뛰는 장면이 담긴 4장의 이미지가 생성된다. 이 4장의 이미지를 그리드 형태로 배열해 마치 한 편의 동영상처럼 보이는 것이다.
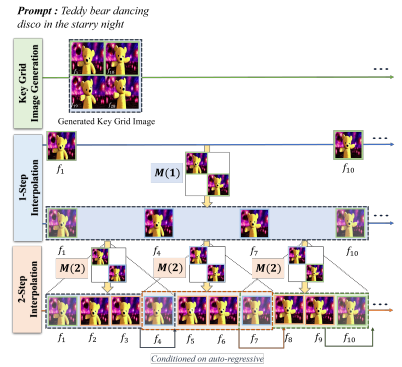
그림4. 추론 과정 이미지
이 모델은 효율적인 학습이 가능해 소량의 데이터로도 긴 영상을 생성할 수 있다. 기존의 이미지 수정 방법론을 비디오에 그대로 적용할 수 있어 실용성도 높다. 해상도 역시 간단하게 확장할 수 있어 교육, 엔터테인먼트 등 다양한 미디어 산업 분야에서 폭넓게 활용될 전망이다.
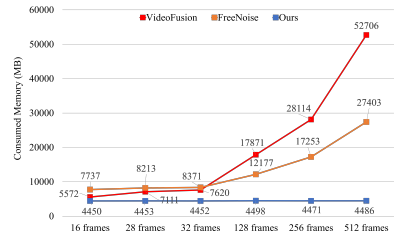
그림5. GPU 메모리 효율성 비교
제1저자 이태경 연구원은 “그리드 확산 모델은 소규모 연구실이나 기업도 경쟁력 있는 AI 연구 가능성을 보여줬다”며, “AI로 제작한 동영상이 실생활과 다양한 산업 분야에서 다양하게 활용될 수 있다”고 설명했다.

그림6. 비디오 에디팅 예시
연구는 세계적인 AI 및 Computer Vision 학술대회 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR) 2024에서 발표됐다.










{kind=link}